Big TCP

Introdução
Como a maioria dos componentes de computação, os componentes de hardware voltados à networking (rede) têm crescido rapidamente com o tempo. E já não temos mais os limites de transmissões existentes há vinte anos atrás (com elances 10-base-t). Hoje em dia, as interfaces de rede podem lidar com uma quantidade massiva de dados de maneira rápida, podendo trafegar múltiplos pacotes de tamanhos diferentes.
MTU comum
A unidade máxima de transferência (MTU) padrão definido pela maioria das interfaces de redes é de 1500 bytes. Isso significa dizer que cada segmento que será transmitido na rede pode transmitir no máximo 1500 bytes. Se a informação que se deseja transmitir for superior ao MTU, ela deverá ser dividida em pedaços de tamanho igual ao MTU.
A responsabilidade de dividir a informação depende do protocolo de rede que o usuário esteja utilizando. Redes que trabalham com a versão 4 do protocolo IP (IPv4) atribuem a atividade de divisão dos pacotes aos dispositivos centrais da rede (ou seja, os roteadores). Nas redes que trabalham com a versão 6 do protocolo IP, a responsabilidade de dividir os pacotes passa a ser dos sistemas finais.
A figura abaixo demonstra um segmento TCP e os campos(também chamado de parâmetros) do cabeçalho TCP.

Figura 1- Segmento TCP
Quando consideramos o tamanho do cabeçalho TCP (20 bytes) e o tamanho do cabeçalho IPv4 (20 bytes), percebemos que a quantidade máxima de dados que uma aplicação pode trafegar em um segmento TCP é de meros 1460 bytes (1500 bytes do MTU - 20 bytes do cabeçalho TCP - 20 bytes do cabeçalho IPv4).
O tamanho do MTU padrão é suficiente para todos os casos?
Em geral, os enlaces de transmissão disponíveis na internet lidam bem com um MTU de 1500 bytes. Mas em redes internas de data-centers, os enlaces de comunicação costumam ser mais robustos e trabalham com uma largura de banda bem maior (em diversos casos, com interfaces de redes que operam a velocidades de 200 à 400 Gbps) e a limitação de MTU de 1500 gera um número enorme de pacotes e consumo de recursos de processamento e largura de banda.
Qual o problema de transmitir dados com um baixo MTU?
Com uma largura de banda tão extensa, transmitir um segmento de 1500 bytes pode gerar milhões de pequenos pacotes para transmitir uma determinada informação e isso desperdiça recursos computacionais como processamento e rede sem necessidade.
Um arquivo de 14800 bytes (cerca de 14,45 KB) que utiliza um MTU 1500 bytes precisa ser dividido em 10 pedaços diferentes antes de ser transmitido pela da rede. Levando em conta que utilizaremos o TCP como protocolo da camada de transporte, para cada segmento transmitido existe um segmento de confirmação (TCP ACK) para indicar ao TCP que a informação chegou no destino e que não foi perdido na rede. Esse comportamento é a garantia de entrega do TCP, que define meios para os pacotes sempre cheguem em ordem ao destino.
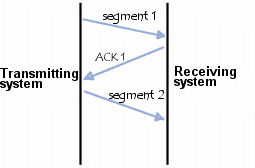
Figura 2- Garantia de entrega do TCP
Então, para transferir os 10 pedaços de informação é necessário criar 10 segmentos TCP, realizando o processo de encapsulamento e desencapsulamento da informação e calculando o tempo de ida e volta (RTT) de cada segmento (da sua transferência à sua confirmação).
Gerar diversos pacotes de rede e realizar todo o processo descrito acima consome 2 principais recursos computacionais: largura de banda e processamento. Enquanto que o segundo é mais barato de expandir e tecnologicamente vem atingindo velocidades bem maiores, o segundo vem crescendo mais de forma menos acelerada quando comparada a primeira opção.
Uma solução para diminuir o número de segmentos TCPs encaminhado seria aumentar o MTU das interfaces de rede caso assim ela suportasse. Jumbo frames é uma técnica que permite aumentar o tamanho dos frames que será transmitido e com isso, permitir que criemos segmentos TCPs bem maiores, diminuindo o número de segmentos criados.
Jumbo frames
São frames de tamanho 6 vezes maiores que o convencional (ou seja, 9000 bytes). Em redes internas de 1Gbps seu uso é muito comum e diversos dispositivos de redes (switches, roteadores) conseguem lidar bem com frames tão grandes.
Embora ainda não seja comum o uso de Jumbo frames na internet (devido a diversos dispositivos ainda não tratarem bem frames maiores que 1500 bytes), para microsserviços que trocam informações dentro de um data-center e que ganham velocidade ao tratarem frames maiores, o uso de jumbo frames já é uma realidade.
Mas o uso de jumbo frames ainda está bastante distante dos limites teóricos que um frame poderia conter. E para data-centers com interfaces de rede velozes e de alta capacidade, o limite de 9000 bytes ainda é pouco. Então, será possível criar frames bem maiores? e se sim, quais elementos são responsável por definir o limite máximo teórico que o frame pode conter?
Basicamente, os protocolos que estão nas camadas 3 e 4 do modelo híbrido (TCP, UDP, IPv4 ou IPv6) possuem campos que define o tamanho de um pacote ou segmento.
Tamanho máximo de um pacote IPv4
O cabeçalho IP versão 4 pode ser visto imagem abaixo:
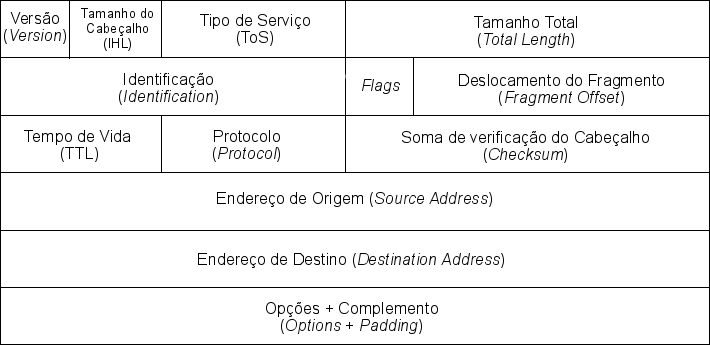
Figura 3 - Cabeçalho IPv4
Nele, o campo Tamanho Total (Total Lenght) define o tamanho total de um pacote (cabeçalho IP + payload) em bytes (um octeto). Esse campo tem tamanho total de 16 bits e abaixo podemos calcular o tamanho máximo que ele pode possuir:
16 bits → 2¹⁶ == 65535 bytes, ou ≅ 64KB
Então, em teoria, poderíamos transmitir no máximo 64KB de informação em um único pacote IP. Somente isso já é capaz de reduzir bastante a quantidade de fragmentos para transferir grandes arquivos pela rede, e por conexão, o processamento dos computadores para criar e ler esses pacotes.
Mas será que esse seria o limite final que um pacote poderia possuir? Quando falamos de tráfego usando IPv4 sim, mas com o IPv6 a história é bem diferente.
Limite de tamanho teórico de um pacote IPv6
O cabeçalho IP versão 6 pode ser visto na imagem abaixo:
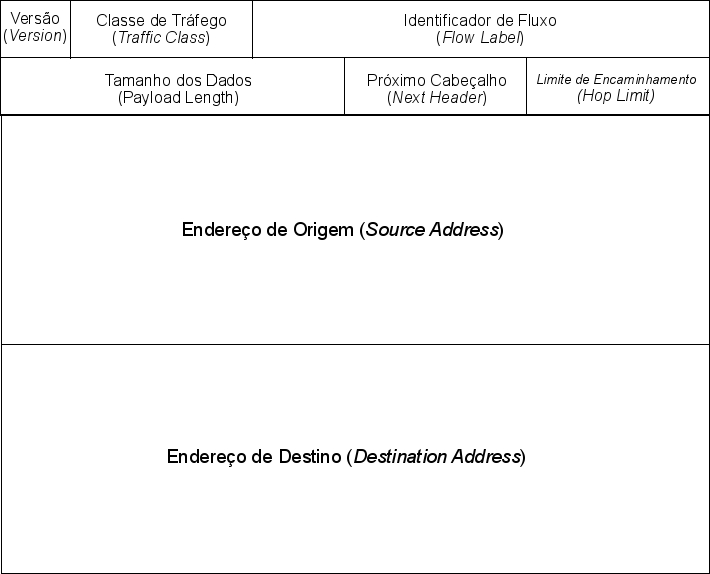
Figura 4 - Cabeçalho IPv6
Da mesma maneira que o cabeçalho IPv4, o cabeçalho IPv6 possui um campo de 16 bits denominado Tamanho dos Dados (Payload Length) que representa o tamanho total do pacote em bytes (opções do cabeçalho + payload). Então, se levássemos apenas essa informação em conta para definir o tamanho de um pacote IPv6, o limite máximo de tamanho seria o mesmo, mas diferentemente do do IPv4, a versão do IPv6 permite extender seu comportamento através de cabeçalhos extras adicionado ao IP. Esse comportamento torna o IPv6 mais adaptável a novas mudanças com o passar do tempo.
E um dos problemas que se observava já na década de 90 foi o tamanho total de um pacote poderia possuir.
O IPv6 Jumbograms (RFC 2675) é uma extensão ao cabeçalho IPv6 (Next-Header) que permite modificar tamanho de um pacote. O novo cabeçalho contém 32 bits e, quando ele está definido com o valor 0, significa dizer que o tamanho do pacote será o máximo possível (2^32 bits, ou cerca de 4 GB em um único pacote!)
O uso de IPv6 Jumbograms elimina a necessidade de trabalhar com múltiplos segmentos TCP, onde, um único segmento TCP já teria toda a informação que se deseja transmitir, sem a necessidade de pequenas fragmentações.
Limites dos segmentos TCP e UDP
O cabeçalho TCP não possui um campo indicando o tamanho máximo do segmento (MSS). Logo, em vias normais, o TCP não faz verificação do tamanho do segmento. Na própria documentação do RFC 2675, é indicado algumas exceções que podem atrapalhar o encaminhamento de dados maiores que 64K. Por exemplo, se o valor de MSS for negociado entre as partes, não poderá ser definido valores maiores que 64KB e o ponteiro de urgência do cabeçalho TCP não pode apontar além dos 64KB.
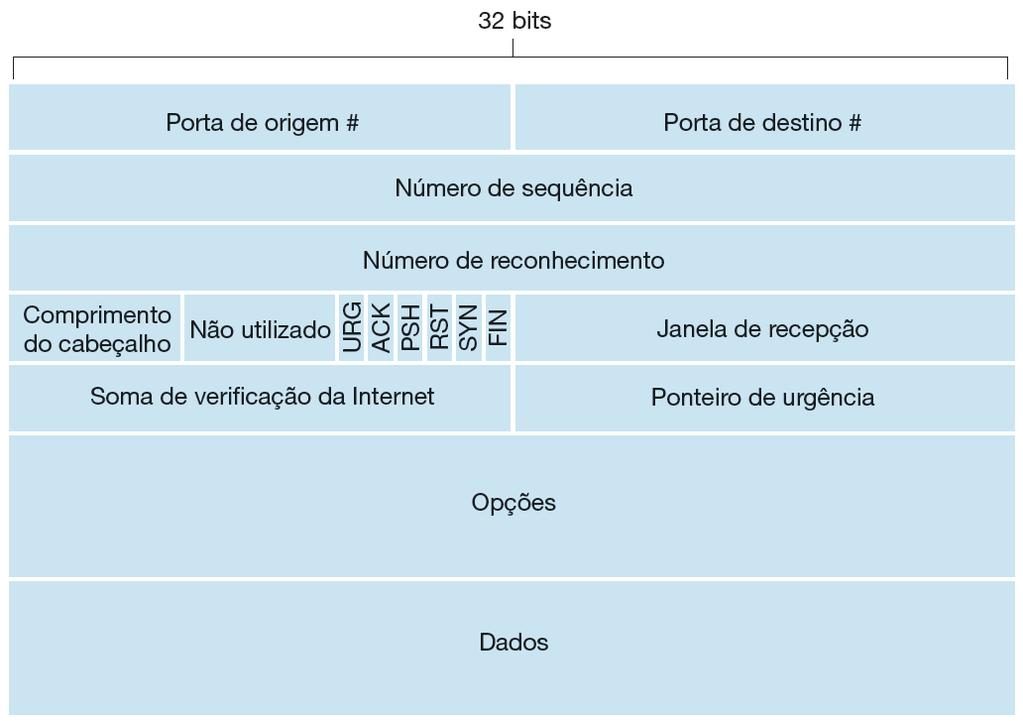
Figura 5 Cabeçalho TCP
O cabeçalho UDP possui um campo de 16 bits denominado Comprimento (Length) que determina o tamanho de um segmento UDP com seu cabeçalho e o payload, definido em bytes. Novamente, quando se utiliza IPv6, o segmento UDP poderá carregar mais que 64KB se o valor do campo Length receber o valor 0.
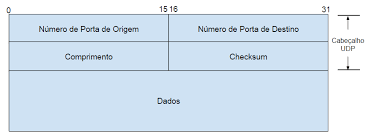
Figura 6- Cabeçalho UDP
Big TCP e o tamanho de um segmento
O kernel do Linux trouxe na sua versão 5.19 o suporte ao Big TCP, permitindo quebrar as barreiras postas de 1500, 9000 ou 65535 bits para placas de rede que suportam alto MTU. Pelos commits realizados, as interfaces de rede que suportarão Big TCP até o momento são:
- ipv6: adicionando hop-by-hop head ao IPv6 jubograms no ip6_output
- ipvlan: habilita suporte a pacotes Big TCP
- mxl4: suporta pacotes Big TCP
- mxl5: suporta pacotes Big TCP
- ipv6/gso
- ipv6/gro
- macvlan: habilita suporte a pacotes Big TCP
Embora futuramente seja possível encontrar pelos enlaces que compões a internet capacidades de MTU maiores, atualmente essas soluções são aplicadas principalmente a redes internas de data-centers que tendem a ser bastante beneficiados da implementação e suporte do BigTCP e tendem a demorar certo tempo até ser implementado em outros ambientes. Os principais motivos são:
- Fora da rede, nem todos os dispositivos do núcleo da rede saberá lidar com pacotes Big TCP e podem tomar duas decisões: Se for IPv4, o pacote será fragmentado em pedaços menores, então a solução não será empregada ao todo. O IPv6 não realiza fragmentação, então vai mandar um ICMPv6 com a mensagem packet too big, sendo necessário fragmentar na origem o segmento em partes menores.
- Mesmo que os dispositivos de rede intermediários possua uma alta largura de banda de transmissão (por exemplo, 100Gbps), ainda seria necessário que os dispositivos estejam rodando a versão 5.19 do Kernel Linux, ou que as fabricantes desses dispositivos fornecessem alguma atualização para suportá-lo.
Referências
Gostou deste artigo?
Aqui estão mais alguns artigos que talvez você goste de ler: